
OCRという外来語を聞いたことがありますか?
OCR―Optical character recognitionの略語、日本語に翻訳すれば、光学文字認識という意味です。つまり、文書の画像(例えば、イメージ、スクリーンショット写真など)を文字コード(テキストなど編集可能のファイル形式)に変換します。イメージだけでなく、PDFファイルの内容をテキスト化にすることもできます。Adobe Acrobat、ApowerPDFなどのPDF編集ソフトにもOCR機能が付いています。
OCRは仕事、勉強また生活の中でよく使われています。一つの例を挙げて説明しましょう。ネットであるPDFファイルをダウンロードしましたが、このPDFをコピー、内容編集、変換はできません。なぜかというと、このPDFファイルは暗号化されたからです。このときはどうすればいいでしょう?裏ワザの一つとして、OCR機能を使って、このPDFファイルをword、テキストに「変換」します。ここで言う「変換」はPDFファイルの変換とは違って、たとえファイルが暗号化されても操作できます。
もう一つの方法は、PDFファイルの内容をスクリーンショットして、OCRでテキスト化します。
もちろん、ネットでスクリーンショットした写真もOCRに認識されます。
人工知能の一つとしてのOCRは飛躍的に発展していますが、認識の正解率が依然として大きな難題である。100%の正解率までの道もまだ遠いです。
そうは言っても、既存のOCR技術の重要性は否定できません。
さて、OCRについて簡単に説明した以上、ここでよく使われるオンラインOCRソフトをいくつかご紹介します。
Online OCR
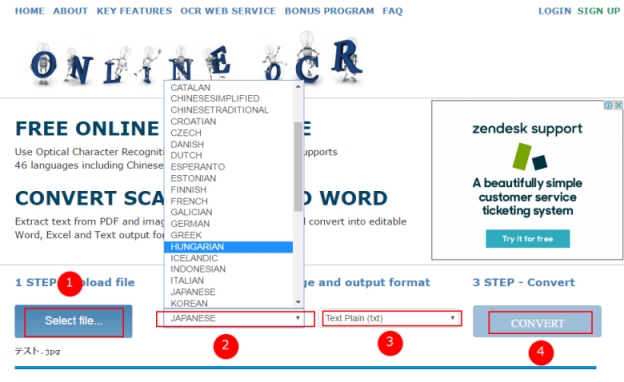
使い方は非常に簡単です。
- 目標ファイルをアップロードする。サポートするフォーマットはPDF and images (JPG, BMP, TIFF, GIF)です。
- 認識するファイルの言語を選択します。合わせて46種類の言語に対応しています。
- 出力形式を選択します。Word、Excel、テキストという三つの出力形式があります。
- Convert(変換)ボタンを押します。目標ファイルは即座に変換されます。
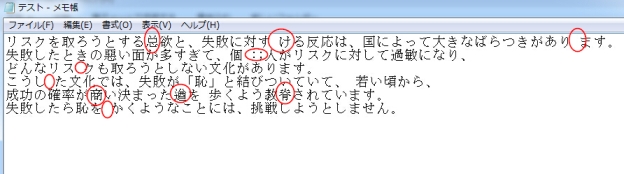
まずは、NHK新聞の一度部分(横文字)をスクリーンショットに撮ってOnline OCRでテキスト化してみます。

赤印をつけているところは間違えました。例えば「浅」「晰」「訃」「晴」という漢字は正しく認識されません。
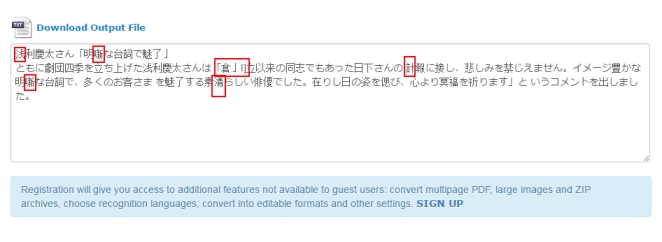
次に、電子書籍の写真(縦文字)をOnline OCRでテキスト化してみます。

元の写真の一番上にある一行文字が認識されません、また、「国」を「111」に間違えました。ほかの部分は問題がありません。
Jinapdf
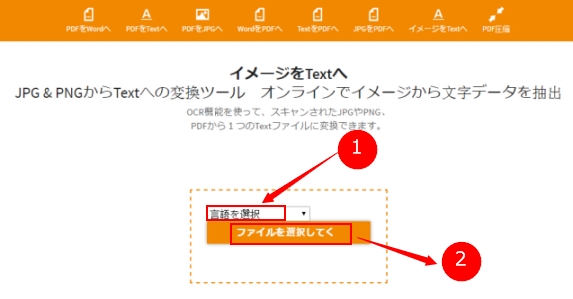
サポートする言語は45種類ありますが、入力ファイルはJPG、PNG、PDF のみ対応しています。また、出力形式はテキストだけです。言語を選択して、目標ファイルをアップロードします。少々待つと、認識が完了します。そして、ローカルディスクにダウンロードします。
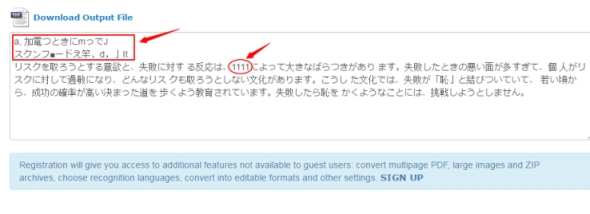
同じくNHK新聞のスクリーンショットをテキスト化してみます。最も不便なところは、行分けしないまま出力されたので、読みにくいです。
ここで、自ら区切りをつけて、内容だけチェックしてみましょう。
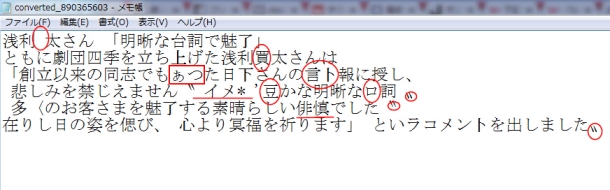
Online OCRを使うより、JinapdfのOCR機能の正解率は比較的に低いです。「慶」「優」という複雑な漢字はさておき、「台」「イメージ」という簡単な内容すら認識できません。また、行分けしないのせいで、文章の句読点は一切認識されていません。しかも、Jinapdfは縦文字の内容も認識できません。
Googleドライブ
厳密に言えば、この機能はOCRとは言えないですが、JPG、PNG、PDFをテキストファイルでダウンロードすることができます。
使い方は少し複雑ですが、以下の手順に従えて操作してみてください。
ステップ1:Googleドライブにログインして、「新規」ボタンをクリック、ファイルをアップロードします。
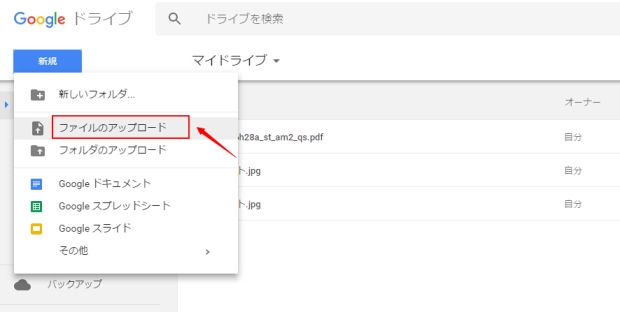
ステップ2:目標ファイルを右クリックして、「アプリを開く」→「Googleドキュメント」を選択して、ファイルをGoogleドキュメントで開きます。
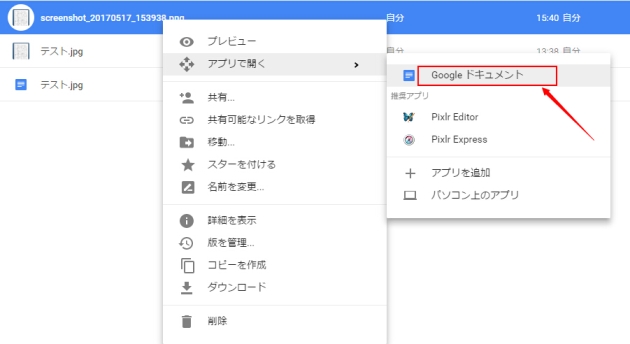
ステップ3:「ファイル」→「形式を指定してダウンロード」→「書式なしテキスト」をクリックして、イメージ写真はテキスト化されます。
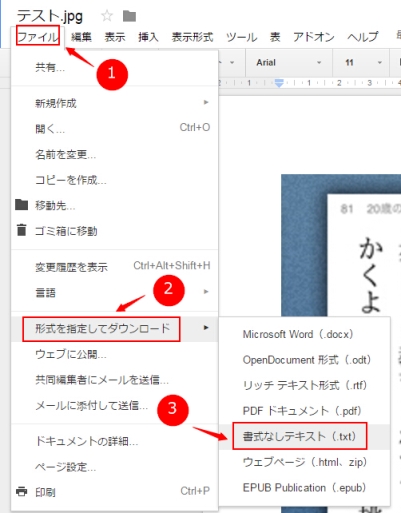
まずは横文字のテキスト化から確認します。

内容には間違いがありますが、一番少ないです。また、テキスト化した内容はファイルとして出力されず、元の写真の下に映します。写真を見ながら、テキストの内容を直すのは便利です。
縦文字のほうはどうでしょう?
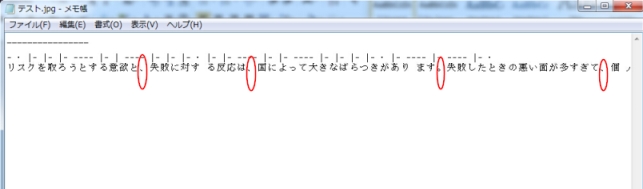
Jinapdfと同じ、行分けはしません。しかし、句読点があります。
ABBYY FineReader Online
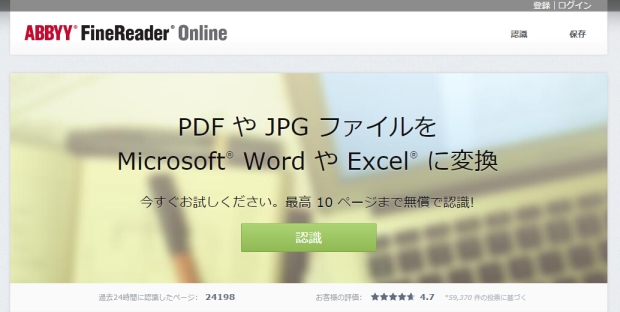
この写真に示された通り、このソフトはオンラインでPDFとJPGファイルをwordやExcelに変換できます。しかし、1ヶ月に試用回数が制限されます。しかも、登録しないと使えません。
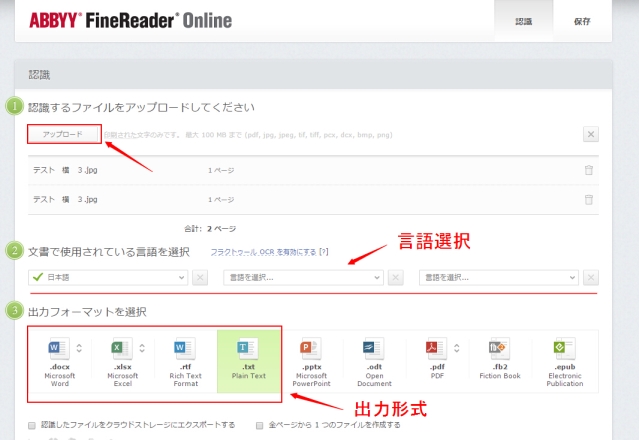
使い方はこちらです。まず、「認識」ページに入ります。そして、ファイルをアップロードして、言語を選択します。複数の言語を選択することができます(同じファイルに日本語や英語などの言語が入っている場合に適用します)。出力形式(Word、Excel、txt、RTF)を選択して認識を始めます。
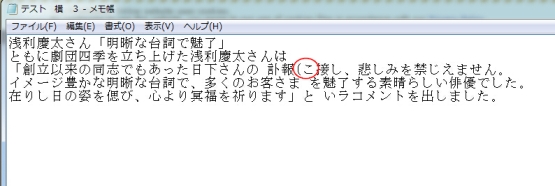
出力したテキストには句読点がありますが、行わけがしません。また、横文字を認識したテキストには一つの間違いしかありませんが、縦文字のほうが間違いが多いです。
Free online OCR
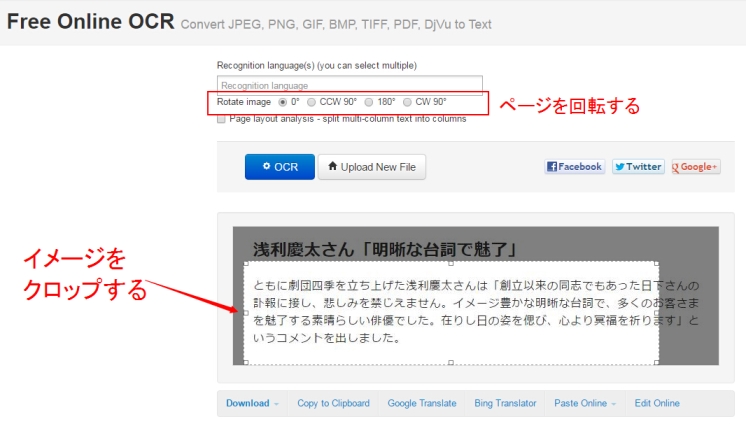
分かりやすいインターフェースになっています。残念ですが、日本語に対応していません。JPEG、PNG、GIF、 BMP、 TIFF、 PDF、DjVu to Textファイルの認識にサポートしています。出力形式は三種類あります、word、PDF、txt。
このOCRソフトの特徴はイメーシを回転したり、必要な部分だけを切り取りしたりすることができます。
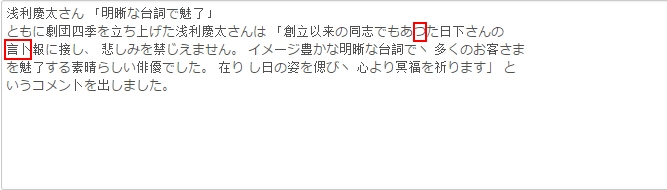
横文字の内容はだいたい認識できますが、縦文字の内容がサポートしていません。
i2OCR
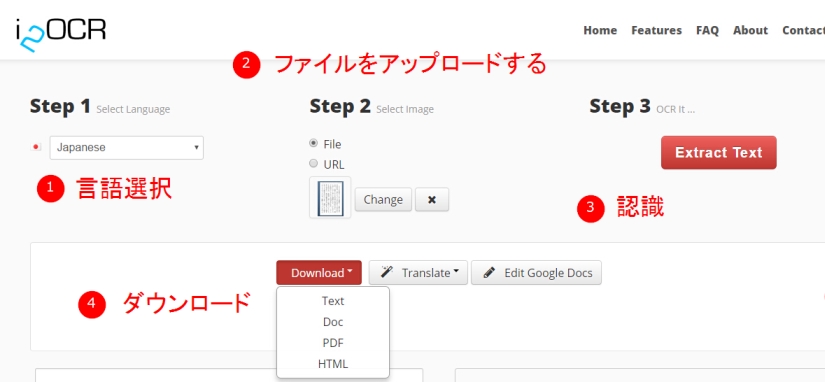
横文字と縦文字両方とも認識できますが、正解率は低くて、文字化けのところも多いです。


直感的に比較するために、下の図表に参照してください。
| 入力形式 | 出力形式 | 横文字 | 縦文字 | 句読点 | 正解率 | |
| Online OCR | PDF 、JPG、BMP、TIFF、GIF | Word、Excel、txt | 対応 | 対応 一番使いやすい | ある | 高い |
| Jinapdf | JPG、PNG、PDF | テキスト | 対応 行分けしない | ✖ | ない | 普通 |
| Googleドライブ | JPG、PNG、PDF | テキスト | 対応 一番使いやすい | 対応 一番使いやすい | ある | 一番高い |
| ABBYY FineReader Online | JPG、PDF | Word、Excel、txt、RTF | 対応 行分けしない | 対応 行分けしない | ある | 高い |
| Free online OCR | JPEG、PNG、GIF BMP、PDF、TIFF、DjVu | word、PDF、txt | 対応 | ✖ | ある | 高い |
| i2OCR | PDF、JPG、URL | txt、word、PDF、HTML | 対応 | 対応 | ある | 低い |
OCR機能を使う時のヒント:
- 手書きの内容は認識されません(あるいは認識しにくい)
- 高解像度、サイズが大きなイメージをアップロードすると、認識の正解率は高くなる。
- 複雑な漢字の認識率は低い。
- OCR機能を使うとき、文字以外の内容は認識されない、文字化けになる。
- 100%の認識率のOCRソフトは存在しません。

コメントを書く